


此前报道称苹果考虑使用 Google 和 OpenAI 的 AI 技术许可用于 iOS 18,而不是开发自己的在线大语言模型。
在视频任务方面,Core 超越了 Gemini Ultra。在语言任务方面,Core 在成熟的基准测试中可与其他前沿模型媲美。
Reka提供三种不同规模的模型——Reka Core, Flash和Edge,以满足不同的业务需求。
Edge:7B 轻量级/本地模型,可部署在边缘设备Flash:21B,速度快,功能强Core:最大的模型,能胜任各种复杂任务
Reka AI 的创始团队由来自 DeepMind、Google Brain 和 FAIR 的研究科学家和工程师组成。总部位于加利福尼亚州的森尼维尔,采用远程优先的工作模式,团队成员遍布加利福尼亚、西雅图、伦敦、苏黎世、香港和新加坡等地。
1、全电动系统:新版Atlas采用完全电动化设计,与之前的液压系统相比,提供了更平滑、更静音的运动性能。
2、增强的力量和灵活性:电动Atlas具有比以往任何一代更强大的力量和更广泛的运动范围,使其能够执行更复杂的操作和任务。
3、实用的工业应用设计:设计目标是应用于真实世界的工业场景,如汽车制造和其他高要求的工业环境,支持复杂的工业操作。
4、先进的软件和AI工具:配备了最新的AI和机器学习工具,如强化学习和计算机视觉,确保机器人能够适应并高效处理复杂的实际情况。
5、Orbit软件平台:提供了一个中央管理平台,用于管理整个机器人车队、场地地图及数字化转型数据,使得整体操作更加高效和集中。
该技术能够在没有任何先前训练的情况下,直接将一种材质从一个图像迁移到另一个图像中的对象上。 ZeST 不仅支持单一材质的迁移,还能处理单一图像中的多重材质编辑。 支持持在设备上快速处理图像,无需依赖云计算或服务器端处理。 该项目是由牛津大学、Stability AI 和 MIT CSAIL 的研究团队共同完成。
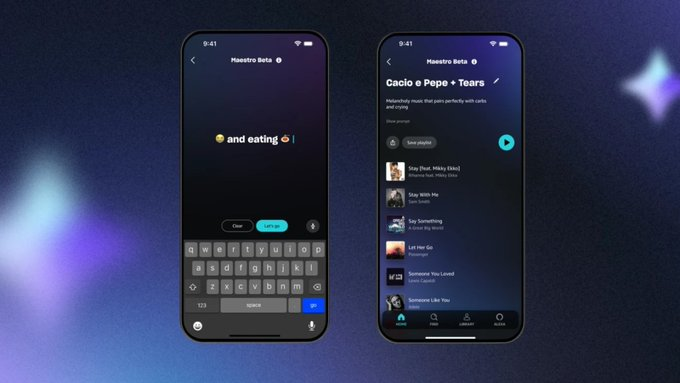
使用范围:目前Maestro在美国的亚马逊音乐服务的一个子集中测试,包括免费的广告支持版本。
更新需求:用户需要更新到亚马逊音乐应用的最新版本,并作为beta测试者在首页和创建播放列表时会看到Maestro选项。
该项目由腾讯开发,该框架结合了现成的多视图扩散模型和基于LRM(大规模重建模型)的稀疏视图重建模型的优势,能够在10秒内创建多样化的3D模型,且精度相当高。

官方宣传称SD3模型在文字到图像生成领域的表现达到或超过了如DALL-E 3和Midjourney v6等行业领先模型,尤其是在字体和提示遵循方面。
Stability AI称仍在持续改进该模型,并没有说明发布日期,应该是可能另有打算,要收费了!

推出了一种名为 Magic Clothing 的新型网络架构,它基于潜在扩散模型(LDM)进行开发,专门处理一项新的图像合成任务——服装驱动的图像合成。
该系统旨在生成根据不同文本提示定制的、穿着特定服装的角色。在这一过程中,图像的可控性至关重要,主要是要确保服装的细节得以保留,并且生成的图像要忠实于文本提示。
为了实现这一点,我们开发了一种服装特征提取器,用以详细捕捉服装的特征,并通过自注意力融合技术,将这些特征有效整合到预训练好的LDMs中,确保目标角色的服装细节不发生改变。
同时,我们还使用了一种称为联合无分类器指导的技术,以平衡服装特征和文本提示在生成图像中的影响。
此外,我们提出的服装提取器是一个可插拔模块,可以应用于多种经过微调的LDMs,并能与 ControlNet 和 IP-Adapter 等其他技术结合使用,进一步提高生成角色的多样性和可控性。
我们还开发了一种名为匹配点LPIPS(MP-LPIPS)的新型评估指标,用于评价生成图像与原始服装之间的一致性。
m6米乐主页 上一篇:【课程简讯】骆仁童老师为郑州某新能源企业解读《从C 下一篇:OpenAI创始人致力建立全球AI联盟 促进人工智

